Variational Autoencoder (VAE) nedir? Autoencoder’dan ne farkı vardır?

Autoencoder modeli, veri sıkıştırma gibi birçok alanda sıkça kullanılan popüler bir modeldir. Peki Autoencoder’ları yeni veya benzer veri üretme için kullanabilir miyiz? Yukarıdaki örnekte olduğu gibi veriler arasında geçiş yapmak için nasıl bir yöntem izlememiz lazım? Üretilen verilerin karakteristiklerini kontrol edebilir miyiz? Bu yazıda bunları yapabilmemizi sağlayan Variational Autoencoder’lardan teknik detaylara girmeden bahsedeceğiz. Daha önceki “Autoencoder (Otokodlayıcı) Nedir?” yazısında Autoencoder’ların nasıl çalıştığı ve ne amaçlarla kullanıldığı konusuna değinmiştik. Eğer Autoencoder’lar hakkında bilgi sahibi değilseniz buradan ilgili yazıya ulaşabilirsiniz.
Standart Autoencoder’larda her girdi Encoder’dan (kodlayıcı) geçirilerek kodlanır ve bir latent vector’e (saklı/belirsiz vektör) dönüştürülür. Bu vektöre kod denir. Daha sonra kod, Decoder’dan (kod çözücü) geçirilerek eski haline getirilir. Variational Autoencoder’larda ise Encoder’dan geçirilen girdi, bir olasılık dağılımı olarak kodlanır. Bu olasılık dağılımını Normal Dağılım (Gauss Dağılımı) olarak düşünürsek, bu dağılımı ifade etmek için ortalama ve varyans değerlerine ihtiyacımız vardır. Yani Variational Autoencoder’larda Encoder çıktısı bir kod değil, ortalama ve varyans değerleridir. Bu ortalama ve varyans değerlerinden örnekleme yapılarak kod elde edilir. Bu kod Decoder ile çözülebilir. Decoder kısmı Autoencoder ve VAE’da aynıdır.

Yukarıdaki şekilde AE ve VAE farkını görebiliriz. AE’de girdi (x) bir koda (z) sıkıştırılır ve tekrar eski haline (x’) dönüştürülür. VAE’de ise girdiden (x) ortalama (µ) ve varyans (σ ²) değerleri elde edilir. Bu değerler kullanılarak kod (z) örneklenir. Bu adıma sampling (örnekleme) adımı denir. Sonrasında yine bu kod çözülerek eski haline (x’) dönüştürülür.
Kayıp Fonksiyonu

VAE’lerin eğitilmesi için farklı bir kayıp fonksiyonu kullanılır. Standart AE’nin eğitilmesi için kullanılan kayıp fonksiyonu reconstruction loss’tur (yeniden oluşturma kaybı), yani girdi ve çıktı arasındaki farktır. Bu farkı hesaplarken genelde MSE kullanılır. VAE’de ise bu kayba ek olarak regularization loss (düzenlileştirme kaybı) veya diğer ismiyle latent loss kullanılır. Bu kayıp özet olarak ortalama ve varyans değerlerinin oluşturduğu dağılım ve Normal Dağılım arasındaki farktır. Bu kaybı hesaplamak için “Kullback–Leibler (KL) Divergence” kullanılır. KL Divergence 2 olasılık dağılımının birbirinden ne kadar farklı olduğunu ölçen bir metriktir. Hesaplama için Encoder çıktısı olan ortalama ve varyans değerlerinin oluşturduğu dağılım N(µ,σ²) ile Normal Dağılım N(0,1) arasındaki KL Divergence değeri alınır. Bu işlem yukarıda 2. formülde gösterildiği gibi formülize edilebilir. Sonuç olarak toplam kayıp, reconstruction loss ve KL Divergence toplamında oluşur.
Reparametrization Trick

Neural Network modelleri backpropagation kullanılarak eğitilir. Teknik olarak VAE’yi eğitmek için önceki paragrafta anlatılan yaklaşımda bir değişiklik yapmak gerekir. Çünkü ortalama ve varyans değerlerinden kod örnekleme işlemi backpropagation için uygun değildir. VAE’yi backpropagation kullanarak eğitebilmek için bir ε değeri kullanılır. Bu değer basitçe Normal Dağılımdan üretilmiş rastgele bir sayıdır. Direkt olarak µ ve σ değerinden kod (z) üretmek yerine “z=µ+σ.ε” formülü ile kod (z) üretilir. Backpropagation sırasında da ε değeri sabit tutularak sistemin eğitilmesi sağlanır. Buna reparametrization trick (yeniden parametreleştirme hilesi) denir. Bu işlemin tek amacı sistemin backpropagation kullanılarak eğitilebilmesini sağlamaktır. Formülasyonda gösterilmese de kodlama yaparken bu şekilde kullanılır.
Eğitim
VAE’yi eğitmek için el yazısı rakam resimlerinden oluşan MNIST veri setini kullandığımızı düşünelim. 2 boyutlu kodlar üreten bir VAE’de her resmi kodlayıp bunları 2 boyutlu bir düzlemde gösterirsek bu düzleme latent space (saklı değer uzayı) diyebiliriz. Aşağıdaki resimde reconstruction loss ve KL Divergence terimlerinin kod dağılımına olan etkisini görüyoruz. İlk grafikte VAE sadece reconstruction loss kullanılarak eğitildiğinde oluşan kod dağılımını görüyoruz. Bu durumda sınıflar (rakamlar) birbirinden farklı yerlere dağılmışlarsa da genel dağılımın ne olduğunu bilmiyoruz. Örneğin 1’den 7’ye doğru geçiş yaparken hiçbir sınıfa denk düşmeyen bölgeler var. Yani latent space bazı bölgelerde boş ve her yerde continuous (sürekli) değil. Bu durumda yeni bir örnek üretmek istediğimizde nasıl örnekleme yapmamız gerektiğini bilmiyoruz. Bazı kodlar da boş alanlara denk düştüğü için hiçbir mantıklı çıktı üretmeyecektir.
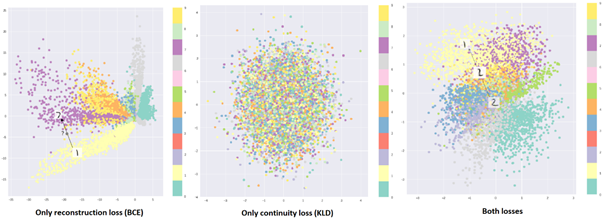
2. grafikte VAE sadece KL Divergence kullanılarak eğitildiğinde oluşan kod dağılımını görüyoruz. Kod dağılımı 0 merkezli ve 1 varyanslı Normal Dağılıma uyuyor ama bu sefer de sınıflar çok iç içe geçmiş ve hangi bölge hangi sınıfa ait göremiyoruz. Bir rakamın hemen yakınında tamamen başka bir rakam olacağı için o rakama benzer bir rakam üretmenin zor olacağını söyleyebiliriz. Ayrıca bu durumda kodların Decoder’dan geçirilerek rakamların yeniden oluşturulması da çok zor olur ve düşük kaliteli sonuçlar üretilir.
3. grafikte ise VAE eğitiminde olması gerektiği gibi, iki kayıp bir arada kullanılınca oluşan durumu görüyoruz. Kodların dağılımı hem Normal Dağılıma uyuyor hem de sınıflar birbirinden ayrı bölgelere dağılmış. Bir rakamdan öbürüne geçiş yaparken boşluk yok ve rakamların benzerlerini üretmek için yakın kod değerleri kullanılabilir. Aynı zamanda yeni rakamlar üretmek istersek de Normal Dağılımdan örnekleme yapabiliriz.

Yukarıdaki örnekte VAE kullanılarak disentanglement (dolanıklık çözme) yapılmış. Normalde koddaki kısımların neyi temsil ettiği belirsizdir. Direkt olarak kodun bir kısmı değiştirilerek, üretilen veri üzerinde istenilen değişikliğin yapılması sağlanamaz. VAE sayesinde koddaki kısımların hangi özelliklere karşılık geldiği çözülerek üretilen verinin karakteristiği kontrol edilebilir. Aşağıdaki resimde ise yine bir başka VAE yapısı tarafından üretilen sahte yüz resimlerini görüyoruz. Bu resimler eğitim verisinde bulunmayan, eğitim bittikten sonra rastgele kod üretilerek oluşturulan sahte resimler.

AE — VAE farkları
- AE’de Encoder kod üretir. VAE’de Encoder ortalama ve varyans değerleri üretir. Bu değerler, örnekleme adımından geçirilerek kod üretilir. Decoder yapısı ise ikisinde de aynıdır.
- AE’de sadece reconstruction loss kullanılır. VAE’de reconstruction loss ve regularizationloss (KL Divergence) toplamı kullanılır.
- AE bir generative (üretici) model değildir. Amacı veriyi sıkıştırıp tekrar açmaktır. VAE bir generative modeldir. Örnekleme yapılarak rastgele kod üretilip, bu kodla yeni veri elde edilebilir. Eski verilerin oluşturduğu kodlara yakın kodlar kullanılarak benzer veri üretilebilir. Veriler arasında interpolasyon yapılabilir. Başka bir generative model için bkz. Generative Adversarial Networks (GAN)
- AE’lerin eğitimi kolaydır. Ekstra parametre gerektirmeden tek bir loss fonksiyonu ile eğitilebilirler. VAE’lerin eğitimi zordur ve parametreler düzgün ayarlanmazsa sistem hiç çalışmayabilir. Özellikle reconstruction ve latent loss arasındaki dengeyi bulmak zor ve uğraştırıcı olabilir. Bu dengeyi sağlamak için regularization loss değeri belli bir sayıyla (β) çarpılarak ağırlığı değiştirilir.
- AE’ler overfitting’e yatkın yapıdadır. VAE’ler, AE’deki overfitting’i azaltmak için kullanılabilir. Genel olarak VAE ekstra özelliklerinden dolayı AE yerine kullanılabilir.
