Generative Adversarial Networks (GAN) alanında okunması gereken 10 makale
GAN’lerin popülerliği her geçen gün artmaya devam ediyor ve önümüzdeki yıllarda düşecek gibi de görünmüyor. Bu yazıda GAN’ler hakkında okunması gereken 10 makaleye değineceğiz. Bu çalışmalar en çok ses getiren ve bu alanda en çok ilerleme kaydeden çalışmalar. Eğer Generative Adversarial Networks hakkında hiç bir bilgiye sahip değilseniz Generative Adversarial Networks (GAN)nedir yazısında gerekli bilgiyi bulabilirsiniz. Önce listeye bir bakalım daha sonra da teker teker inceleyelim.
1- Deep Convolutional GAN
2- Conditional GAN
3- Wasserstein GAN
4- Improved Techniques for Training GANs
5- pix2pix
6- CycleGAN
7- BigGAN
8- ProGAN
9- StyleGAN
10- SinGAN
DCGAN
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
GAN’ler GAN nedir yazısında da detaylıca anlatıldığı gibi birbiriyle çekişen 2 yapay sinir ağını konu alır. Bu 2 ağın hangi tip olduğu önemli değildir. İşte DCGAN özet olarak GAN’lerde Convolutional (Evrişimli) ağların kullanılmasını öneriyor. Bildiğimiz gibi convolutional ağlar resimler konusunda başarılı. Eğer bir resim üretmek istiyorsak akla ilk gelen şey GAN ağlarında Convolution kullanmak olacaktır. Burada Ayırt Edici ağ, ilk katmanı resim boyutu, son katmanı ise tek bir nöron olan bir convolutional ağ. Üretici ağ ise ilk katmanı gürültü vektörü son katmanı resim boyutu olan bir Deconvolutional (Ters Evrişimli) ağ. Bu işlem için Deconvolution ismi en yaygın isim olsa da transposed convolution, upconvolution gibi isimler de literatürde kullanılabiliyor. Eğer GAN’leri resimler için kullanacaksanız bakmanız gereken ilk çalışmalardan birisi DCGAN’dir.

CGAN
Orijinal GAN modeli rastgele bir şekilde gerçekçi veriler üretmeyi amaçlar. Mesela kedi fotoğrafları ile eğittiğimiz bir model her seferinde farklı rastgele bir kedi resmi üretecektir. Peki ya biz spesifik olarak siyah bir kedi resmi veya yavru kedi resmi üretmek istiyorsak? İşte Conditional GAN adından da anlaşılacağı gibi bir koşul parametresi ekleyerek, üretilen verinin bazı karakteristiklerini kontrol etmeyi amaçlıyor. Hem Üretici ağa hem de Ayırt Edici ağa ekstra bir girdi verisi eklenerek, üretilen verinin belirtilen koşula uyması sağlanıyor. Bu ekstra girdi verisini dahil etmenin en kolay yolu normal girdiyle birleştirmek veya verinin sonuna eklemek. Örneğin siyah ve beyaz kedilerden oluşan veri setinde beyaz renge 0 siyah renge 1 değerini verdiğimizi düşünelim. Siyah renkli bir kedi resmi üretmek istediğimizde üretici ağın girdisi gürültü ve sonuna eklenmiş bir 1 değeri, ayırt edici ağın girdisi ise gerçek ve sahte resimlerin sonuna eklenmiş 1 değeri olacaktır. Bu sayede üretici ağ 1 değerini gördüğünde siyah bir kedi üretmesi gerektiğini anlayacak, ayırt edici ağ ise üretilen resmin hem gerçekçi olup olmadığını hem de aldığı 1 değeri ile siyah koşuluna uyup uymadığına bakacaktır. Makalede test için en popüler veri seti olan MNIST veri seti kullanılmıştır. El yazısı rakamlardan oluşan bu veri setinde her seferde rastgele bir rakam üretmek yerine istenen rakamın üretilmesi sağlanmıştır.

WGAN
Bu makale GAN’in loss (hata/kayıp) fonksiyonunu değiştirerek daha dengeli bir GAN eğitimine olanak vermektedir. Matematik ağırlıklı ve çok sayıda ispat içeren bu makaleyi anlamak biraz zor olabilir. Özet olarak bu makale standart GAN’lerde loss fonksiyonu olarak kullanılan “Jensen-Shannon Divergence” yerine “Wasserstein Distance”ın kullanılmasını öneriyor. “Jensen-Shannon divergence” 2 olasılıksal dağılımın farkını ölçen bir uzaklık formülü. Üretici ağ bu uzaklığı küçültecek şekilde eğitiliyor. Bu makalede, bu yöntemin dengesizlik gibi sorunlara yol açtığından dolayı yerine Wassterstein Distance fonksiyonunun kullanılması gerektiğinin ispatı yapılıyor. Wasserstein Distance’ın diğer adı ise Earth Mover’s Distance (Toprak taşıma mesafesi). Olasılıksal dağılımları toprak yığınları olarak düşünürsek, bu formül bir toprak yığınını diğer bir toprak yığınına benzetebilmek için ne kadar toprağın yer değiştirmesi gerektiğini hesaplıyor. Makalenin yaptığı öneri, daha dengeli bir eğitim sağladığı ve daha iyi veriler ürettiği için genelde standart GAN fonksiyonu yerine tercih ediliyor.

Improved Techniques for Training GANs
GAN’in yaratıcısı Ian Goodfellow’un da yazarlarından biri olduğu bu çalışma, GAN’leri iyileştirmek ve daha dengeli bir eğitim sağlamak için yapılabilecek önerilerden oluşuyor. GAN’lerin en büyük sorunlarından biri dengesizlik (unstability) ve salınım (oscillation) problemi. Bu çalışmada bu problemlerin çözümüne yardımcı olacak bir çok metoddan bahsediliyor. Her biri ayrı bir yazının konusu olabilecek “feature matching, minibatch discrimination, historical averaging, one-sided label smoothing, virtual batch normalization” gibi konular detaylı bir şekilde anlatılıyor. Çalışma GAN’leri daha iyi anlamak ve ileri seviye teknikleri öğrenmek açısından çok faydalı.
pix2pix
Image-to-Image Translation with Conditional Adversarial Nets
En popüler GAN uygulamalarından biri olan pix2pix resimden resme dönüştürme işlemini amaçlıyor. Siyah beyaz resimlerin renkli resimlere dönüştürülmesi, çizimlerin renklendirilmesi, gündüz çekilen fotoğrafların geceye, verilen etiketlerin sokak veya bina resimlerine dönüştürülmesi, uydu fotoğraflarından navigasyon haritalarının çıkarılması gibi işlerin hepsi aynı model kullanılarak yapılabiliyor. Çalışmada Ayırt Edici ağ için kullanılan PatchGAN sistemi, gerçek ve sahte resimleri ayırt etmek için bütün resme bakmak yerine, resmi parçalara bölerek parça bazında değerlendirme yapıyor. Çalışmanın sitesinde ( affinelayer.com/pixsrv ) tarayıcınız üzerinde deneyebileceğiniz interaktif bir demo mevcut.
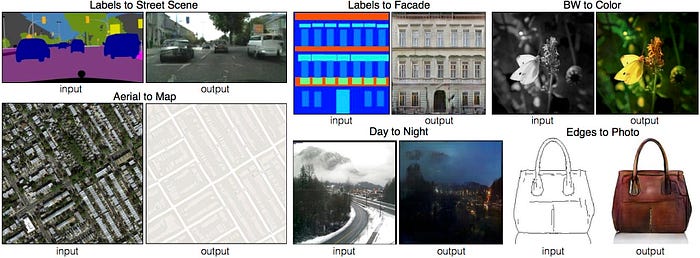
CycleGAN
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Çalışma bir resmi farklı bir konsepte dönüştürmeyi amaçlıyor. Mesela kışın çekilmiş karlı bir dağ resmi yazın çekilse nasıl olurdu veya yeşil bir elma kırmızı olsa nasıl görünürdü? Bu çalışmadaki asıl yenilik, sistemin eşli veriye gerek duymaması. Yani bu işlemi yapmak için her verinin 2 durumda da nasıl görüneceğini gösteren bir veri setine ihtiyacınız yok. Aynı elmanın hem yeşil hem kırmızı halinin fotoğraflarına veya aynı dağın hem yazın hem kışın çekilmiş fotoğraflarına gerek duyulmuyor. Sistem iç içe geçmiş 2 tane GAN kullanarak resmi önce istenen içeriğe dönüştürüyor, sonra tekrar eski haline dönüştürüyor. Sonucun yeni içeriğe ne kadar uyum sağladığını gösteren bir kayıp ve orijinal haline ne kadar benzediğini gösteren başka bir kayıp hesaplanıyor. Daha sonra bu kayıpların azaltılması sağlanıyor. Bu döngü sayesinde hem orijinal haline çok benzeyen hem de istenen dönüşümü gerçekleştirmiş resimler üretiliyor. Mesela at -> zebra -> at döngüsü yapılarak bir atın, zebra olsaydı nasıl görüneceği bulunabiliyor.
Bu sistem ressamların portreleri ile eğitilirse, verilen bir fotoğrafı o ressam çizse nasıl çizerdi sorusunun cevabı bulunabilir. Bunun gibi çalışmalar sayesinde sanatçıları ölümsüz kılmak ve sürekli yeni eserler ürettirmek mümkün olabilir.

BigGAN
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Gerçek adı farklı olsa da kısaca BigGAN olarak bilinen bu çalışma Google’a ait DeepMind şirketi tarafından yapıldı. Amaç çok büyük ölçeklerde GAN eğitmenin başarılarını ve zorluklarını görmekti. Bugüne kadar yapılmış en büyük GAN modeli, en büyük veri setlerinden biriyle en yüksek kaynaklar kullanarak eğitildi. Kullanılan veri setinde tam 300 milyon resim bulunuyor. Resimler 512x512 çözünürlükte ve 18000 sınıfa ayrılacak şekilde etiketlenmiş. Sistem 512 TPU (ekran kartı “GPU” benzeri Google’ın ürettiği yapay zeka işlemcisi) kullanılarak 48 saatte eğitilmiş. Bu çalışma yayınlandığında, bu kadar yüksek çözünürlükte resim üretebilen tek çalışmaydı. Bu kadar büyük ölçekte bir çalışma yapabilmek için elinizde Google’ın sahip olduğu imkanların bulunması gerekiyor. Bu çalışmanın daha sonra yayınlanan “light” versiyonunu eğitmek için bile 8 ekran kartına ihtiyacınız var. Çalışma, bu kadar büyük ölçekte çalışıldığında daha önce ortaya çıkmayan değişik tipte sorunların ortaya çıktığını ve bunların çözümlerini gösteriyor. Ayrıca daha çok veri, daha büyük model, daha fazla kaynak üçlemesi ile daha büyük başarı yakalanmaya devam edildiğinin de bir göstergesi olarak kabul ediliyor.

ProGAN
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Nvidia tarafından yapılan çalışma, kademeli olarak bir GAN’in nasıl büyütüleceği ve her kademede nasıl daha yüksek çözünürlüklü resimler üretileceği üzerine. Her kademede, eğitim yapıldıktan sonra modele yeni katmanlar ekleniyor ve model büyütülüyor. Her kademe, bir önceki kademenin ürettiği resimleri daha yüksek çözünürlüğe taşıyor. Çözünürlük yükseldikçe GAN’lerdeki dengesizlik de arttığından, bu yöntem aynı zamanda GAN eğitimini de daha dengeli hale getiriyor. Sistem önce 4x4 çözünürlükte bir resim üretecek şekilde eğitiliyor. Sonra bu üretilen resmin çözünürlüğü 8x8'e çıkarılıyor, bir sonraki kademede 16x16'ya ve daha sonra 1024x1024'e kadar devam ediyor.
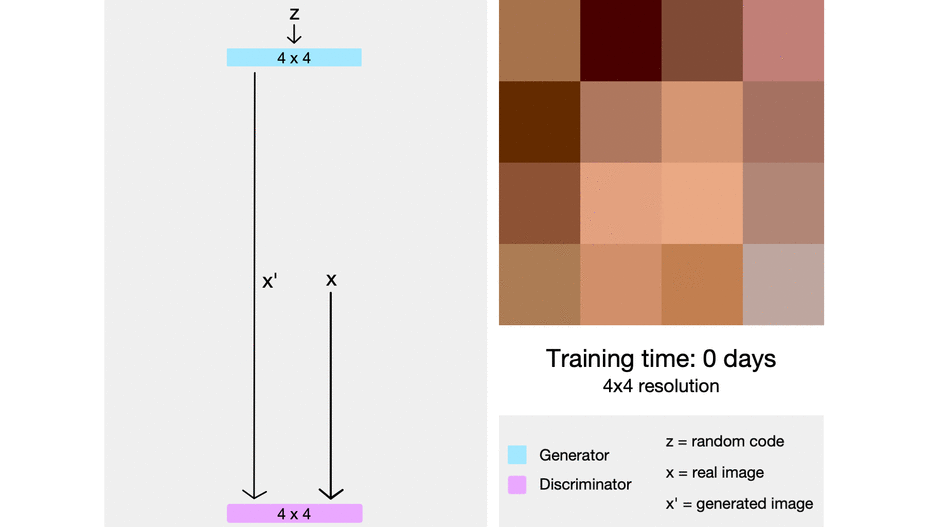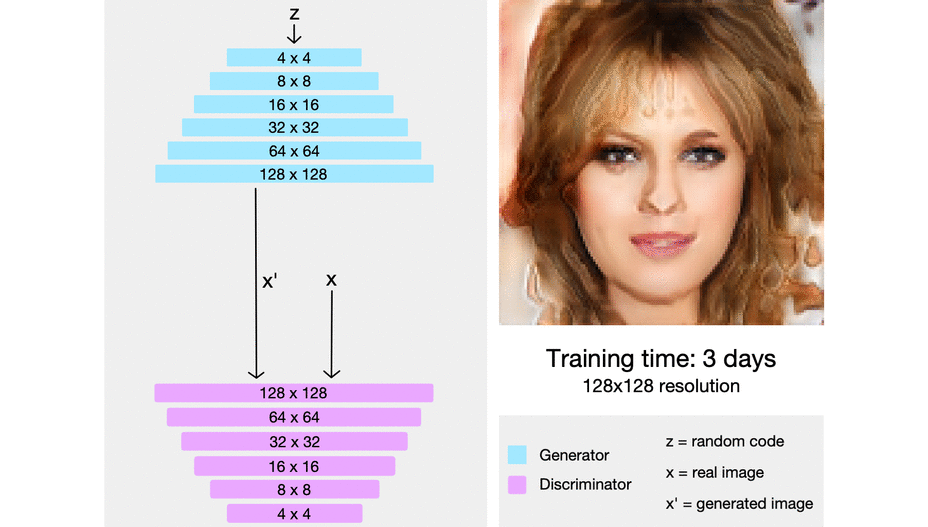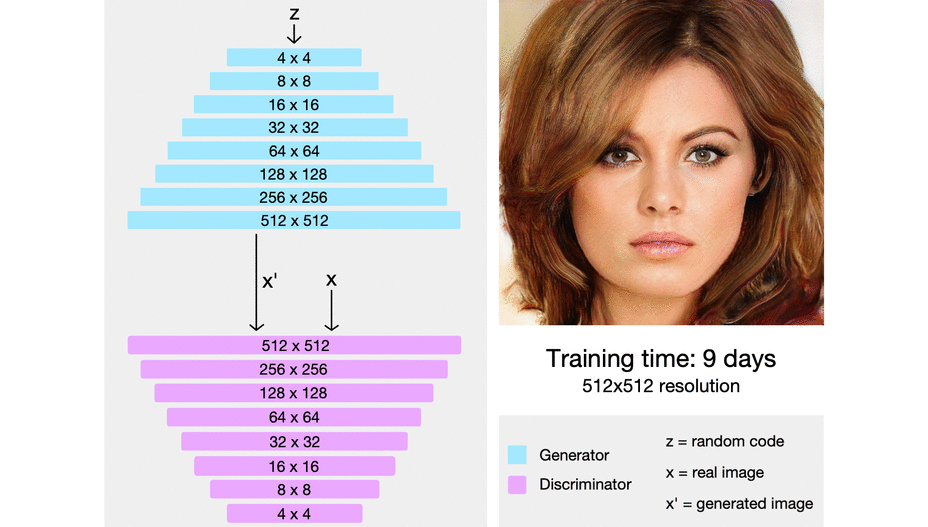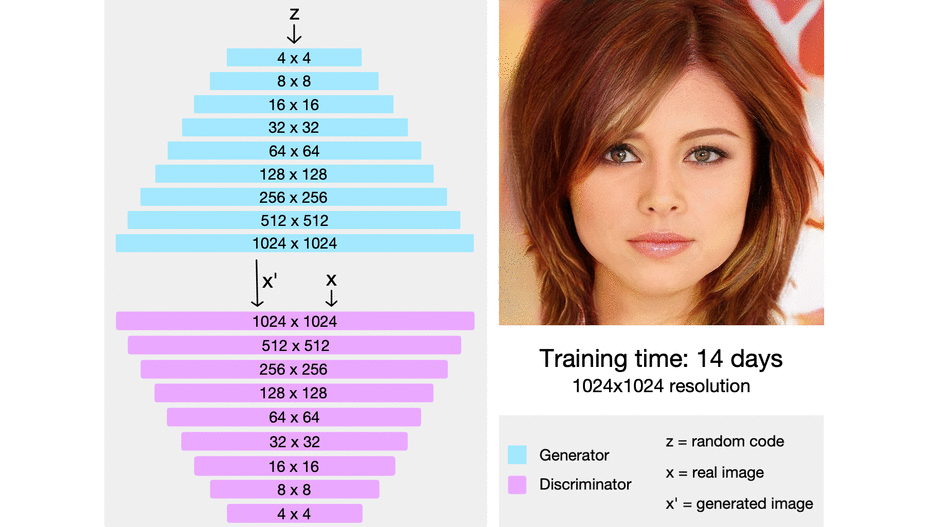
StyleGAN ve StyleGAN2
A Style-Based Generator Architecture for Generative Adversarial Networks
Nvidia tarafından yapılan bir başka çalışma olan StyleGAN’in amacı gerçekçi yüz resimleri üretmek. Ürettiği gerçeğinden ayırt edilemez yüz resimleri sayesinde bu alandaki tartışmasız en başarılı çalışma. Çalışmanın orjinalinden yaklaşık 1 yıl sonra 2. versiyonu yayınlandı. Bu versiyonda direkt olarak yeni bir GAN mimarisi önermek yerine GAN’ler üzerinde değişik yöntemler kullanılarak, daha iyi ve kontrol edilebilir çıktılar üretilmesi amaçlanıyor. Önerilen sistem yüzün açısı, çiller, saç rengi gibi bir çok niteliğin unsupervised (gözetimsiz) öğrenilebilmesini sağlıyor. Her ne kadar bu yöntemler sadece yüz üretme için sınırlı olmasa da en büyük başarıyı bu alanda sağladığı için bu özelliğiyle ön plana çıkıyor.
Üretilen sahte resimlerin hem insanlar hem de yapay zeka sistemleri tarafından gerçeğinden ayırt edilememesi bir çok sorunu ve etik tartışmayı da beraberinde getirdi. Bu modelin bir web sitesine dönüştürülmüş versiyonu da var. thispersondoesnotexist.com sitesine her girdiğinizde sizin için yeni bir sahte yüz resmi üretiyor.

SinGAN
SinGAN: Learning a Generative Model from a Single Natural Image
Deep Learning alanındaki en önemli konferanslardan biri olan ICCV 2019’da en iyi makale ödülünü alan çalışma sadece 1 resim kullanarak yeni resimler üretilmesini sağlıyor. Sistem çok katmanlı bir GAN yapısı kullanıyor. Her katmanda ayrı bir GAN modeli var ve her GAN’in çıktısı bir sonraki GAN’e veriliyor. Gittikçe büyüyen çözünürlükte gerçekçi resimler elde ediliyor. Resmi pencerelere bölerek alt parçalar elde ediliyor ve bu alt parçalar veri seti olarak kullanılıyor. Bu sistem sayesinde yeni resimler üretme, çözünürlük yükseltme, resimden video üretme, resimdeki parçaları düzenleme, boyamadan resme dönüştürme gibi bir çok işlem tek bir resim kullanılarak yapılabiliyor. GAN’lerin değişik mimariler kullanılarak tek bir resim ile bile eğitildiklerinde ne kadar güçlü olabileceğini gösteren çalışma ilerde daha çok ses getirecektir.


