Autoencoder (Otokodlayıcı) nedir? Ne için kullanılır?
Soldaki resim MNIST veri setinden alınan gerçek el yazısı rakamlardan oluşuyor. Sağdaki resim ise soldaki resimlerin tam 150 kat sıkıştırılıp tekrar açılmış halini gösteriyor. Bu işlem Autoencoder’lar ile gerçekleştiriliyor. Autoencoder’lar sayesinde veri, fark edilmeyecek kadar az kayıpla onlarca kat sıkıştırılabiliyor. Peki Autoencoder’lar bunu nasıl yapıyor? Gerçek hayatta başka kullanım alanları neler? Autoencoder ile başka hangi işlemler yapılabilir? Bu yazıda bu soruların cevaplayacağız.
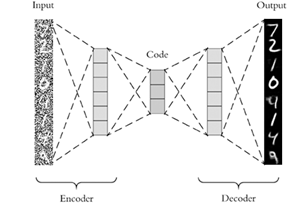
Autoencoder’lar Deep Learning alanındaki en popüler modellerden birisidir. İsminden de anlaşılacağı gibi herhangi bir veriyi koda dönüştürmeyi otomatik olarak öğrenmeyi amaçlamaktadır. 2 kısımdan oluşur: Encoder (Kodlayıcı) ve Decoder (Kod çözücü). Bu 2 kısım eğitim aşamasında sanki tek bir modelmiş gibi beraber eğitilir. Eğitim bittikten sonra ise bu modeller ayrılarak veriyi sıkıştırmak ve sıkıştırılmış veriyi açmak için kullanılır. Örneğin veri bir yerden bir yere taşınacaksa, göndericiye Encoder, alıcıya ise Decoder konularak daha az veri taşınması sağlanabilir.

Autoencoder modelinin amacı, verilen veriyi sıkıştırıp olabildiğince az kayıpla tekrar üretmektir. Bu nedenle sistemin kayıp fonksiyonu (loss) çıktı ve girdi arasındaki farktır, yani output — input olarak ifade edilebilir (genelde MSE kullanılarak hesaplanır). Üretilen kod ise orta katmanın çıktısı alınarak elde edilir. Bu katmana bottleneck layer (darboğaz) denir ve elde edilecek kodun büyüklüğünü belirler. Yani bu katman ne kadar fazla sıkıştırma yapılacağını belirlemiş olur.
İlk örnekteki resimler 28x28 çözünürlükte yani 784 değişkenden oluşuyor. Sistem bottleneck büyüklüğü 5 olan bir Autoencoder ile eğitildi ve kayıp değeri 0.1 olarak hesaplandı. Bu durumda her resim 784 değişken yerine 5 değişkenle tanımlanmış olur. Sıkıştırma büyüklüğünü de bu orta katman belirler. Kaybımız ise 10% civarında olarak düşünülebilir. Tabi ki 10% kaybın ne kadar önemli olduğu tamamen veriye bağlıdır. Bazı verilerde %1 kayıp bile kabul edilemezken, bizim örneğimizdeki resimlerdeki gibi 10% kayıp gözle zor fark edilecek kadar önemsiz olabilir.

Bottleneck layer’da üretilen değere kod veya latent vector (örtük/belirsiz vektör) denir. Burada yapılan kodlama değişkendir. Model her eğitimde farklı kodlama parametreleri kullanabilir. Bir resme karşılık gelen kod her eğitimde farklı olabilir. Ayrıca koddaki değerlerin resimde neye karşılık geldiği de belirsizdir. Input veri ve kod arasındaki ilişki bilinmezdir. Örneğin bottleneck layer 2 değerden oluşuyorsa, her resme karşılık gelen 2 değerli bir kod vardır. Değerleri z1 ve z2 olarak düşünürsek, her resim 2 boyutlu düzlemde bir noktaya karşılık gelmektedir. Bu 2 boyutlu düzleme ise latent space denir. Aşağıdaki resimde bu örneğin oluşturduğu latent space ve bu latent space’deki noktaların Decoder’dan geçtikten sonra ürettiği çıktılar görülebilir.

Kayıplı/Kayıpsız sıkıştırma
Sıkıştırma teknikleri lossy ve lossless (kayıplı ve kayıpsız) olarak ikiye ayrılır. İsminden de anlaşılabileceği gibi bu teknikler sıkıştırılan veri tekrar açıldığında kayıp olup olmayacağını belirler. Bazı uygulamalar kayıpsız sıkıştırmaya ihtiyaç duyarlar. Örneğin bilgisayar programlarında herhangi bir kayıp o programı kullanışsız hale getirir. Bu durumda kayıp kabul edilemez. Aynı şekilde, bir mesajlaşma uygulamasında da karşı tarafa gönderdiğimiz mesajın harfi harfine aynı şekilde ulaşmasını bekleriz. Bu gibi durumlar kayıpsız sıkıştırma kullanılmasını gerektirir. WinRar, WinZip gibi uygulamalar kayıpsız sıkıştırma yöntemleri kullanır. Sıkıştırılan dosyayı birebir aynı şekilde tekrar açabilirler. Ama fotoğraf veya ses dosyalarındaki kayıp sorun olmayabilir. Rahatsız edecek seviyede kayıp olmadığı sürece daha düşük çözünürlükte resim veya daha düşük kalitede ses karşı tarafa iletilebilir. Autoencoder’lar kayıplı sıkıştırma metodlarıdır. Veriyi en az kayıpla sıkıştıracak şekilde eğitilseler de veriyi sıfır kayıpla sıkıştıracak şekilde çalışmazlar. Bu her ne kadar teorik olarak mümkün olsa da hem kullanım amacına aykırıdır hem de verimlilik olarak diğer metodlara karşı dezavantajlı konuma düşmesine neden olur. Ayrıca kayıpsız sıkıştırma, Autoencoder’larda overfitting (ezberleme) göstergelerinden birisidir. Bununla beraber eğitim hangi tip veri ile yapılmışsa, sıkıştırma başarısı sadece o veriye özgüdür. Kedi fotoğrafları ile eğitilen bir Autoencoder araba resimlerini sıkıştırmada başarısız olacaktır.

Kullanım alanları
Feature Extraction (Öznitelik Çıkarma): Autoencoder’lar veriyi sıkıştırırken daha düşük boyutta en fazla bilgiyi tutacak şekilde öğrenirler. Yani verideki en önemli noktaları tutarlar. Bu sayede tespit edilebilen verideki önemli noktalar birçok başka iş için (sınıflandırma, tanıma, bölümleme vs.) kullanılabilir.
Dimension Reduction (Boyut Azaltma): Autoencoder’lar, büyük boyuttaki verileri daha düşük boyuta indirgemek, gereksiz boyutları elimine etmek veya veriyi daha yoğun (dense) temsil etmek için PCA gibi diğer dimension reduction teknikleri yerine gittikçe artan sıklıkta kullanılmaktadırlar.
Denoising (Gürültü giderme): Autoencoder’lara input olarak gürültülü veri verilerek gürültü giderme için eğitilebilir. Örneğin, elimizdeki veri setine sentetik olarak gürültü eklersek ve hatayı hesaplarken gürültüsüz veri ile farkını kullanırsak model sadece input’u tekrar üretmeyi değil, gürültüsünü de gidermeyi öğrenecektir.
Resim renklendirme/tamamlama: Son dönemde popüler olan uygulamalardan biri olan siyah beyaz resimleri renkli resimlere dönüştürme işlemi de Autoencoder kullanılarak yapılabilir. Elimizdeki renkli resimleri önce siyah beyaza dönüştürürsek, elimizde her resmin hem siyah beyaz hem renkli versiyonları bulunur. Bu sayede bu ikisi arasındaki ilişkiyi modele öğretebiliriz. Aynı şekilde çizimleri renklendirme veya fotoğraflardaki eksik/yırtık kısımları tamamlama da bu yöntemle yapılabilir.

Yeni veri üretme: Aynı Generative Adversarial Network’lerle (GAN) yapıldığı gibi Autoencoder’ların bir türü olan Variational Autoencoder (VAE) kullanılarak da yeni veriler üretilebilir. VAE’ler Autoencoder’lardan farklı olarak bottleneck layer’da belirli bir olasılıksal dağılım öğrenirler. Bu sayede bu dağılımdan rastgele kodlar kullanılarak yeni veriler üretilebilir. Modele kedi fotoğrafları verilerek yeni kedi fotoğrafları veya 3B modeller verilerek yeni 3B modeller üretilebilir, çözünürlükleri yükseltilebilir. Variational Autoencoder’lar ile ilgili daha detaylı bilgiyi gelecek yazıda bulabilirsiniz. Ayrıca Generative Adversarial Networks (GAN) hakkında da GAN nedir yazısından bilgi edinebilirsiniz.
Bahsettiğimiz kullanım alanları, akla ilk gelen kullanım alanları olsa da Autoencoder’ların bunların haricinde çok fazla kullanım alanı vardır. Deep Learning çalışmalarında Autoencoder’lar veri üzerinde bir preprocessing (önişleme) tekniği olarak sıklıkla kullanılırlar. Çalışmalarda sıkıştırılmış veri kullanılması hem zamandan hem de gerekli işlem gücünden tasarruf etmemizi sağlar.
